Author: Kaiwan N Billimoria, kaiwanTECH
Date: 13 July 2017
DUT (Device Under Test):
Hardware platform: Qemu-virtualized Versatile Express Cortex-A9.
Software platform: mainline linux kernel ver 4.9.1, kexec-tools, crash utility.
First, my attempt at setting up the Raspberry Pi 3 failed; mostly due to recurring issues with the bloody MMC card; probably a power issue! (see this link).
Anyway. Then switched to doing the same on the always-reliable Qemu virtualizer; I prefer to setup the Vexpress-CA9.
In fact, a supporting project I maintain on github – the SEALS project – is proving extremely useful for building the ARM-32 hardware/software platform quickly and efficiently. (Fun fact: SEALS = Simple Embedded Arm Linux System).
So, I cloned the above-mentioned git repo for SEALS into a new working folder.
The way SEALS work is simple: edit a configuration file (build.config) to your satisfaction, to reflect the PATH to and versions of the cross-compiler, kernel, kernel command-line parameters, busybox, rootfs size, etc.
Setup the SEALS build.config file.
Screenshot: the build_SEALS.sh script initial screen displaying the current build config: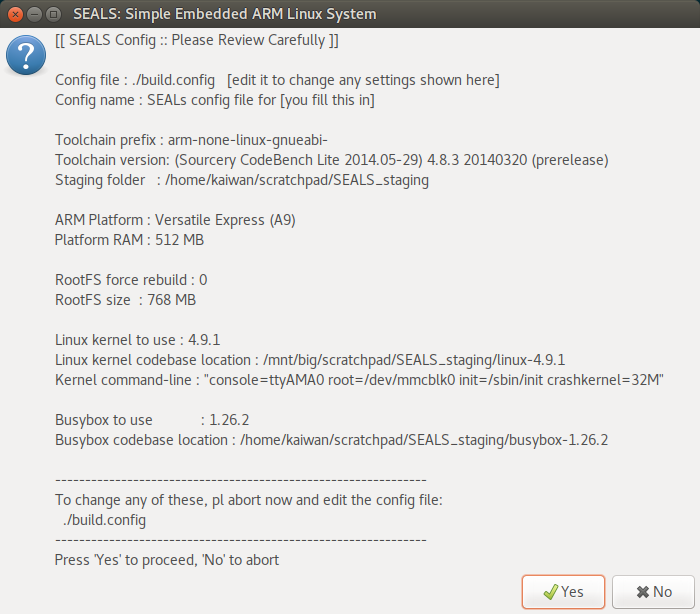
<<
Relevant Info reproduced below for clarity:
…
Toolchain prefix : arm-none-linux-gnueabi-
Toolchain version: (Sourcery CodeBench Lite 2014.05-29) 4.8.3 20140320 (prerelease)
Staging folder : <…>/SEALS_staging
ARM Platform : Versatile Express (A9)
Platform RAM : 512 MB
RootFS force rebuild : 0
RootFS size : 768 MB
Linux kernel to use : 4.9.1
Linux kernel codebase location : <…>/SEALS_staging/linux-4.9.1
Kernel command-line : “console=ttyAMA0 root=/dev/mmcblk0 init=/sbin/init crashkernel=32M”
Busybox to use : 1.26.2
Busybox codebase location : <…>/SEALS_staging/busybox-1.26.2
…
>>
Screenshot: build_SEALS.sh second GUI screen, allowing the user to select actions to take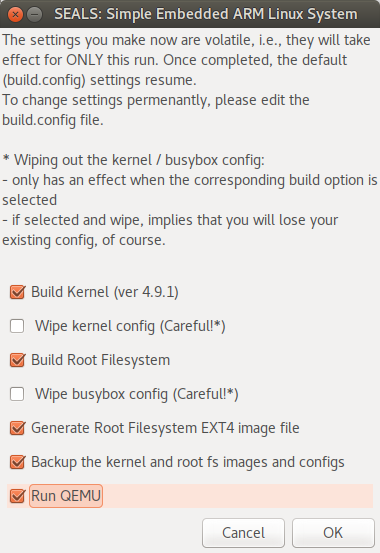
Upon clicking ‘OK’, the build process starts:
I Boot Kernel Setup
- kernel config: must carefully configure the Linux kernel. Please follow the kernel documentation in detail:
https://www.kernel.org/doc/Documentation/kdump/kdump.txt [1]In brief, ensure these are set:
CONFIG_KEXEC=y
CONFIG_SYSFS=y << should be >>
CONFIG_DEBUG_INFO=y
CONFIG_CRASH_DUMP=y
CONFIG_PROC_VMCORE=y
“Dump-capture kernel config options (Arch Dependent, arm)
To use a relocatable kernel, Enable “AUTO_ZRELADDR” support under “Boot” options:
AUTO_ZRELADDR=y”
- Copy the ‘kexec’ binary into the root filesystem (staging tree) under it’s sbin/ folder
-
We build a relocatable kernel so that we can use the same ‘zImage’
for the dump kernel as well as the primary boot kernel:
“Or use the system kernel binary itself as dump-capture kernel and there is no need to build a separate dump-capture kernel.
This is possible only with the architectures which support a relocatable kernel. As of today, i386, x86_64, ppc64, ia64 and arm architectures support relocatable kernel. ...”
- the SEALS build system will proceed to build the kernel using the cross-compiler specified
- went through just fine.
II Load dump-capture (or kdump) kernel into boot kernel’s RAM
Do read [1], but to cut a long story short
-
Create a small shell script kx.sh - a wrapper over kexec – in the root filesystem:
#!/bin/sh
DUMPK_CMDLINE="console=ttyAMA0 root=/dev/mmcblk0 rootfstype=ext4 rootwait init=/sbin/init maxcpus=1 reset_devices"
kexec --type zImage \
-p ./zImage-4.9.1-crk \
--dtb=./vexpress-v2p-ca9.dtb \
--append="${DUMPK_CMDLINE}"
[ $? -ne 0 ] && {
echo "kexec failed." ; exit 1
}
echo "$0: kexec: success, dump kernel loaded."
exit 0
- Run it. It will only work (in my experience) when (for this iMX6 system):
- you’ve passed the kernel parameter ‘crashkernel=32M’
- verified that indeed the boot kernel has reserved 32MB RAM for the dump-capture kernel/system:
RUN: Running qemu-system-arm now ...
qemu-system-arm -m 512 -M vexpress-a9 -kernel <...>/images/zImage \
-drive file=<...>/images/rfs.img,if=sd,format=raw \
-append "console=ttyAMA0 root=/dev/mmcblk0 init=/sbin/init crashkernel=32M" \
-nographic -no-reboot -dtb <...>/linux-4.9.1/arch/arm/boot/dts/vexpress-v2p-ca9.dtb
Booting Linux on physical CPU 0x0
Linux version 4.9.1-crk (hk@hk) (gcc version 4.8.3 20140320 (prerelease) (Sourcery CodeBench Lite 2014.05-29) ) #2 SMP Wed Jul 12 19:41:08 IST 2017
CPU: ARMv7 Processor [410fc090] revision 0 (ARMv7), cr=10c5387d
CPU: PIPT / VIPT nonaliasing data cache, VIPT nonaliasing instruction cache
OF: fdt:Machine model: V2P-CA9
...
ARM / $ dmesg |grep -i crash
Reserving 32MB of memory at 1920MB for crashkernel (System RAM: 512MB)
Kernel command line: console=ttyAMA0 root=/dev/mmcblk0 init=/sbin/init crashkernel=32M
ARM / $ id
uid=0 gid=0
ARM / $ ./kx.sh
./kx.sh: kexec: success, dump kernel loaded.
ARM / $
Ok, the dump-capture kernel has loaded up.
Now to test it!
III Test the soft boot into the dump-capture kernel
On the console of the (emulated) ARM-32:
ARM / $ echo c > /proc/sysrq-trigger
sysrq: SysRq : Trigger a crash
Unhandled fault: page domain fault (0x81b) at 0x00000000
pgd = 9ee44000
[00000000] *pgd=7ee30831, *pte=00000000, *ppte=00000000
Internal error: : 81b [#1] SMP ARM
Modules linked in:
CPU: 0 PID: 724 Comm: sh Not tainted 4.9.1-crk #2
Hardware name: ARM-Versatile Express
task: 9f589600 task.stack: 9ee40000
PC is at sysrq_handle_crash+0x24/0x2c
LR is at arm_heavy_mb+0x1c/0x38
pc : [<804060d8>] lr : [<80114bd8>] psr: 60000013
sp : 9ee41eb8 ip : 00000000 fp : 00000000
...
[<804060d8>] (sysrq_handle_crash) from [<804065bc>] (__handle_sysrq+0xa8/0x170)
[<804065bc>] (__handle_sysrq) from [<80406ab8>] (write_sysrq_trigger+0x54/0x64)
[<80406ab8>] (write_sysrq_trigger) from [<80278588>] (proc_reg_write+0x58/0x90)
[<80278588>] (proc_reg_write) from [<802235c4>] (__vfs_write+0x28/0x10c)
[<802235c4>] (__vfs_write) from [<80224098>] (vfs_write+0xb4/0x15c)
[<80224098>] (vfs_write) from [<80224d30>] (SyS_write+0x40/0x80)
[<80224d30>] (SyS_write) from [<801074a0>] (ret_fast_syscall+0x0/0x3c)
Code: f57ff04e ebf43aba e3a03000 e3a02001 (e5c32000)
Loading crashdump kernel...
Bye!
Booting Linux on physical CPU 0x0
Linux version 4.9.1-crk (hk@hk) (gcc version 4.8.3 20140320 (prerelease) (Sourcery CodeBench Lite 2014.05-29) ) #2 SMP Wed Jul 12 19:41:08 IST 2017
CPU: ARMv7 Processor [410fc090] revision 0 (ARMv7), cr=10c5387d
CPU: PIPT / VIPT nonaliasing data cache, VIPT nonaliasing instruction cache
OF: fdt:Machine model: V2P-CA9
OF: fdt:Ignoring memory range 0x60000000 - 0x78000000
Memory policy: Data cache writeback
CPU: All CPU(s) started in SVC mode.
percpu: Embedded 14 pages/cpu @81e76000 s27648 r8192 d21504 u57344
Built 1 zonelists in Zone order, mobility grouping on. Total pages: 7874
Kernel command line: console=ttyAMA0 root=/dev/mmcblk0 rootfstype=ext4 rootwait
init=/sbin/init maxcpus=1 reset_devices elfcorehdr=0x79f00000 mem=31744K
...
ARM / $ ls -l /proc/vmcore << the dump image (480 MB here) >>
-r-------- 1 0 0 503324672 Jul 13 12:22 /proc/vmcore
ARM / $
Copy the dump file (with cp or scp, whatever),
get it to the host system.
cp /proc/vmcore <dump-file>
ARM / $ halt
ARM / $ EXT4-fs (mmcblk0): re-mounted. Opts: (null)
The system is going down NOW!
Sent SIGTERM to all processes
Sent SIGKILL to all processes
Requesting system halt
reboot: System halted
QEMU: Terminated
^A-X << type Ctrl-a followed by x to exit qemu >>
... and done.
build_SEALS.sh: all done, exiting.
Thank you for using SEALS! We hope you like it.
There is much scope for improvement of course; would love to hear your feedback, ideas, and contribution!
Please visit : https://github.com/kaiwan/seals .
$
IV Analyse the kdump image with the crash utility
CORE ANALYSIS SUITE
The core analysis suite is a self-contained tool that can be used to
investigate either live systems, kernel core dumps created from dump
creation facilities such as kdump, kvmdump, xendump, the netdump and
diskdump packages offered by Red Hat, the LKCD kernel patch, the mcore
kernel patch created by Mission Critical Linux, as well as other formats
created by manufacturer-specific firmware.
...
A whitepaper with complete documentation concerning the use of this utility
can be found here:
https://crash-utility.github.io/crash_whitepaper.html [3]
...
The crash binary can only be used on systems of the same architecture as
the host build system. There are a few optional manners of building the
crash binary:
o On an x86_64 host, a 32-bit x86 binary that can be used to analyze
32-bit x86 dumpfiles may be built by typing "make target=X86".
o On an x86 or x86_64 host, a 32-bit x86 binary that can be used to analyze
32-bit arm dumpfiles may be built by typing "make target=ARM".
...
Ah. To paraphrase, Therein lies the devil, in the details.
[Update: Apr 2019:]
To make this more clear: one must install the following prereq packages (I did this on an x86_64 Ubuntu 18.10 system):
sudo apt install gcc-multilib
sudo apt install libncurses5:i386 lib32z1-dev
[UPDATE : 14 July ’17
I do have it building successfully now. The trick apparently – on x86_64 Ubuntu 17.04 – was to install the lib32z1-dev package! Once I did, it built just fine. Many thanks to Dave Anderson (RedHat) who promptly replied to my query on the crash mailing list.]
I cloned the ‘crash’ git repo, did ‘make target=ARM’, it fails with:
...
../readline/libreadline.a ../opcodes/libopcodes.a ../bfd/libbfd.a
../libiberty/libiberty.a ../libdecnumber/libdecnumber.a -ldl
-lncurses -lm ../libiberty/libiberty.a build-gnulib/import/libgnu.a
-lz -ldl -rdynamic
/usr/bin/ld: cannot find -lz
collect2: error: ld returned 1 exit status
Makefile:1174: recipe for target 'gdb' failed
...
Still trying to debug this!
Btw, if you’re unsure, pl see crash’s github Readme on how to build it.
So, now, with a ‘crash’ binary that works, lets get to work:
$ file crash
crash: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.2, for GNU/Linux 2.6.32, …
$ ./crash
crash 7.1.9++
Copyright (C) 2002-2017 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
[…]
crash: compiled for the ARM architecture
$
To examine a kernel dump (kdump) file, invoke crash like so:
crash <path-to-vmlinux-with-debug-symbols> <path-to-kernel-dumpfile>
$ <...>/crash/crash \
<...>/SEALS_staging/linux-4.9.1/vmlinux ./kdump.img
crash 7.1.9++
Copyright (C) 2002-2017 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
[...]
GNU gdb (GDB) 7.6
Copyright (C) 2013 Free Software Foundation, Inc.
[...]
WARNING: cannot find NT_PRSTATUS note for cpu: 1
WARNING: cannot find NT_PRSTATUS note for cpu: 2
WARNING: cannot find NT_PRSTATUS note for cpu: 3
KERNEL: <...>/SEALS_staging/linux-4.9.1/vmlinux
DUMPFILE: ./kdump.img
CPUS: 4 [OFFLINE: 3]
DATE: Thu Jul 13 00:38:39 2017
UPTIME: 00:00:42
LOAD AVERAGE: 0.00, 0.00, 0.00
TASKS: 56
NODENAME: (none)
RELEASE: 4.9.1-crk
VERSION: #2 SMP Wed Jul 12 19:41:08 IST 2017
MACHINE: armv7l (unknown Mhz)
MEMORY: 512 MB
PANIC: "sysrq: SysRq : Trigger a crash"
PID: 735
COMMAND: "echo"
TASK: 9f6af900 [THREAD_INFO: 9ee48000]
CPU: 0
STATE: TASK_RUNNING (SYSRQ)
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
0 0 0 80a05c00 RU 0.0 0 0 [swapper/0]
> 0 0 1 9f4ab700 RU 0.0 0 0 [swapper/1]
> 0 0 2 9f4abc80 RU 0.0 0 0 [swapper/2]
> 0 0 3 9f4ac200 RU 0.0 0 0 [swapper/3]
1 0 0 9f4a8000 IN 0.1 3344 1500 init
[...]
722 2 0 9f6ac200 IN 0.0 0 0 [ext4-rsv-conver]
728 1 0 9f6ab180 IN 0.1 3348 1672 sh
> 735 728 0 9f6af900 RU 0.1 3344 1080 echo
crash> bt
PID: 735 TASK: 9f6af900 CPU: 0 COMMAND: "echo"
#0 [<804060d8>] (sysrq_handle_crash) from [<804065bc>]
#1 [<804065bc>] (__handle_sysrq) from [<80406ab8>]
#2 [<80406ab8>] (write_sysrq_trigger) from [<80278588>]
#3 [<80278588>] (proc_reg_write) from [<802235c4>]
#4 [<802235c4>] (__vfs_write) from [<80224098>]
#5 [<80224098>] (vfs_write) from [<80224d30>]
#6 [<80224d30>] (sys_write) from [<801074a0>]
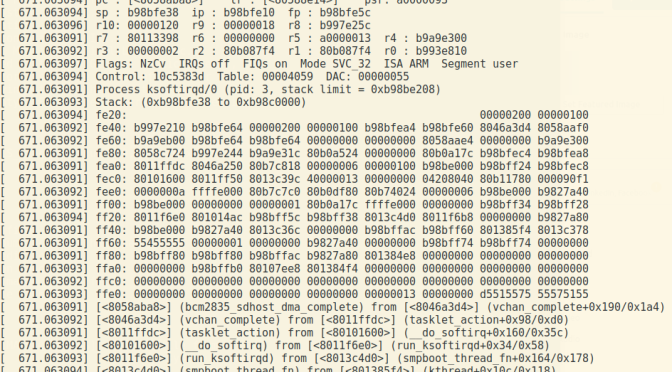
pc : [<76e8d7ec>] lr : [<0000f9dc>] psr: 60000010
sp : 7ebdcc7c ip : 00000000 fp : 00000000
r10: 0010286c r9 : 7ebdce68 r8 : 00000020
r7 : 00000004 r6 : 00103008 r5 : 00000001 r4 : 00102e2c
r3 : 00000000 r2 : 00000002 r1 : 00103008 r0 : 00000001
Flags: nZCv IRQs on FIQs on Mode USER_32 ISA ARM
crash>
And so on …
Another thing we can do is use gdb – to a limited extent – to analyse the dump file:
From [1]:
…
Before analyzing the dump image, you should reboot into a stable kernel.
You can do limited analysis using GDB on the dump file copied out of
/proc/vmcore. Use the debug vmlinux built with -g and run the following
command:
gdb vmlinux <dump-file>
Stack trace for the task on processor 0, register display, and memory
display work fine.
Also, [3] is an excellent whitepaper on using crash. Do read it.
All right, hope that helps!